Graph Database
What is graph database?
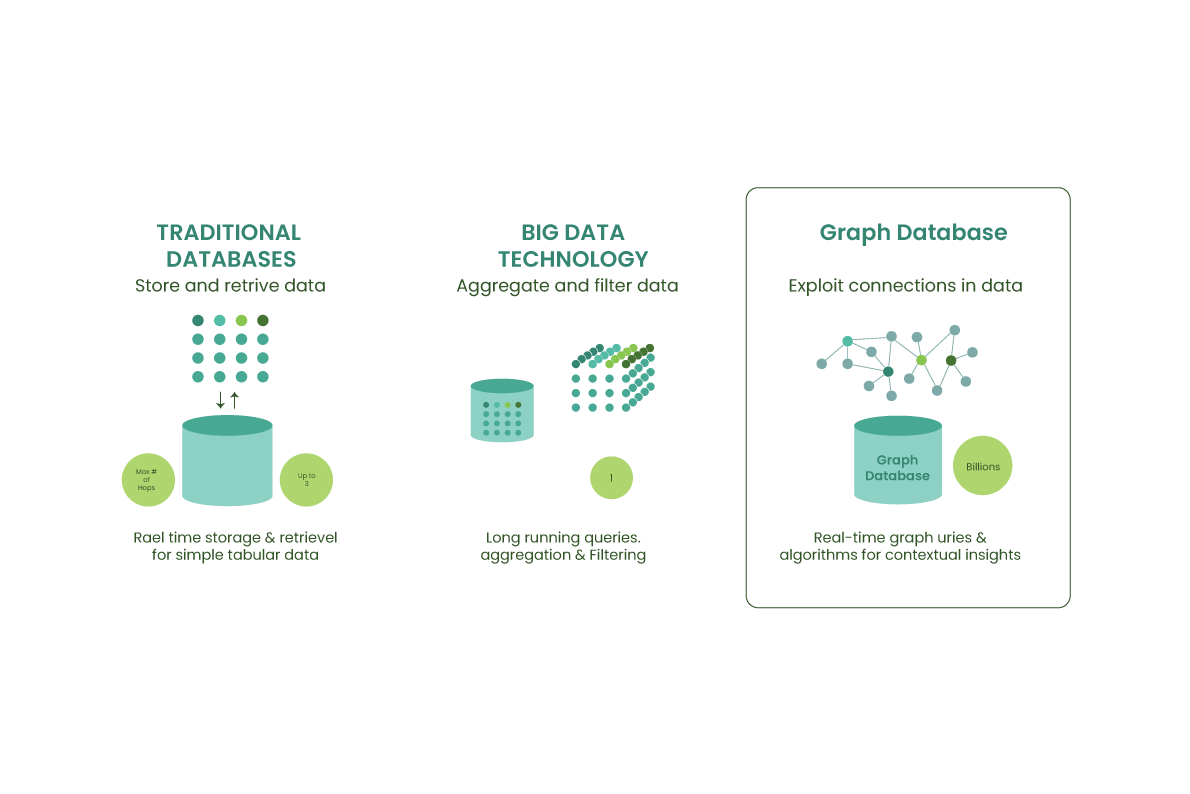
A graph database is defined as a specialized, single-purpose platform for creating and manipulating graphs. Graphs contain nodes, edges, and properties, all of which are used to represent and store data in a way that relational databases are not equipped to do. It uses nodes, edges, and properties instead of tables or documents to represent and store data. The edges represent relationships between the nodes. This helps in retrieving data more easily and, in many cases, with one operation. Graph databases are OLTP-based No-SQL databases.
How graph database works?
Graph databases are NoSQL, Big data & OTLP-based data bases, which stores & represent data in the form of Graph. In a layman's terms it is like writing in a whiteboard & bringing model to reality. It is designed to represent complex relationships between data in a more natural and intuitive way than traditional databases. One key advantage of graph databases is that they can easily handle complex and diverse relationships between entities. This makes them particularly useful for applications that need to perform complex queries or analyses on large and diverse datasets.
How Graph database works?
1) Nodes: Data is represented as nodes, which can be thought of as individual entities or objects. For example, in an ERP, any data point might be represented as a node.
2) Edges: Relationships between nodes are represented as edges, which can be thought of as the connections between different entities. For example, in an ERP, a relation between two data points might be represented as an edge.
3) Properties: Nodes and edges can have properties associated with them, which represent additional information about the data. For example, a product node might have properties such as name, category, type & other details.
4) Data is modeled as a graph: The first step in using a graph database is to define the schema or data model. This involves defining the entities, relationships, and properties that will be stored in the database.Here, Graph data modeling in different from traditional modeling, where the same models are used for multiple usecases.
5) Data Input: Once the schema has been defined, data can be input into the database. This can be done manually or through automated processes such as data pipelines.
6) Data Storing: Graph databases store data as nodes and relationships. A node represents an entity, such as a person, place, or thing, and a relationship represents a connection or association between two nodes.Each node and relationship can have properties that define its characteristics, Example in a person node, a person's name, address, or age is a property.
7) Querying: Graph databases use a query language to access and manipulate the data. The most common query language used in graph databases are Cypher Or SparkQL
8) Graph Query Language: Graph databases use a graph query language to retrieve data, these query language helps to perform operations on the graph. (Cypher is used in Neo4j, a popular graph database) These languages allow users to specify complex queries and traversals, such as finding all nodes that are two or three degrees away from a given node.
9) Traversing the Graph: To retrieve data from a graph database, you traverse the graph by starting at a node and following its relationships to other nodes. You can do multiple activities on the data as needed.
10) Scalability: Graph databases are designed to scale horizontally by adding more nodes to the database cluster, allowing for better performance and availability.
11) Graph algorithms can be used for analysis: Graph databases can also be used for graph analysis, which involves running algorithms on the graph to identify patterns and relationships. For example, graph analysis can be used to identify clusters of highly connected nodes, or to find the shortest path between two nodes in the graph.
Why graph database?
Solves Many to many relationship problems like executing multiple complex queries in traditional databases are time taking, and Low latency with large scalable data. Most Graph database providers help with a suite including Graph database & Graph Analytics Engine along with Visualization, so that every type of user will be under a single platform & help any users to discover more insights over their data by using graph algorithms, pattern matching queries & Visuals. Graph databases are converged supporting, multi models, multi-tenant, Multi workload, and Multi-dimensional storage under one single DB engine. The data team has less time to manage schema for incoming data from multiple sources. Handling Schemas & potential changes are time-consuming challenges; however, NoSQL databases are popular for their ease of use due to flexible schemas. Whereas Graph databases are indexed free & have multi-directional flexibility with the Graph model. E.g. if there are any changes that come in regulatory or compliance then in traditional systems you have to rework or rebuild the entire data model, whereas in the Graph model is easy to add another node & build a relationship in minutes. Graph databases can power up data warehouses & data lakes simplifying metadata management, by configuring all your data with unlimited scalability & limit your need to set up complicated ETL & data transformation.
What is Graph Model?
Frequent schema changes, managing a huge volume of data, real-time query response time, and more intelligent data activation requirements are done by graph model.
What is Graph Analytics?
Graph analytics is another commonly used term, and it refers specifically to the process of analyzing data in a graph format using data points as nodes and relationships as edges. Graph analytics requires a database that can support graph formats; this could be a dedicated graph database or a converged database that supports multiple data models, including graphs.
What is Graph Algorithm?
Graph algorithms are specifically designed to analyze relationships and behaviors among data in graphs which make it possible to understand things that are difficult to see with traditional methods. When it comes to analyzing graphs, algorithms explore the paths and distance between the vertices, the importance of the vertices, and the clustering of the vertices. The algorithms will often look at incoming edges, the importance of neighboring vertices, and other indicators to help determine their importance. For example, graph algorithms can identify what individual or item is most connected to others in social networks or business processes. The algorithms can identify communities, anomalies, common patterns, and paths that connect individuals or related transactions.
What is Future of Graph databases?
Graph databases and graph techniques have been evolving as computing power and big data have increased over the past decade. it’s become increasingly clear that they will become the standard tool for analyzing a brave new world of complex data relationships. As businesses and organizations continue pushing the capabilities of big data and analysis, the ability to derive insights in increasingly complex ways makes graph databases a must-have for today’s needs and tomorrow’s successes.